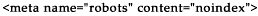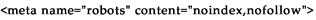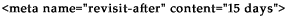With all of the
SEO tips, tricks, and tutorials available to you, probably the easiest to achieve is the use of the robots.txt file. This is a simple file that gives instructions to search engine robots, or spiders, on how to crawl your website, and which files and directories to stay out of, and to not index in their databases.
In an earlier tutorial by Clint Dixon, he showed you how to write a robots.txt file, and what information to include, such as User-Agent and the Disallow directive, instructing the search engine spiders on how to crawl your site. In this article, I want to build upon what he showed you, and give you more information on the importance of the robots.txt in your SEO efforts, and some of the consequences of not having one, or having one written incorrectly.
Behavior of Search Engines When Encountering Robots.txtSearch engines behave differently upon encountering, or not, the robots.txt file during a crawl. You only have to follow your web stats to know that the robots.txt is one of the most requested files by search engine spiders. Many spiders check the robots.txt file first before ever performing a crawl, and some even pre-empt crawls by checking for the presence of, and commands in, the file; only to leave and come back another day. In the absence of this file, many search engine spiders will still crawl your website, but you will find that even more will simply leave without indexing. While this is seen as one of the most extreme consequences of excluding the robots.txt file, I will also show you consequences that I consider to be far worse.
Some of the major search engine spiders and robots have distinct behavior patterns upon reading the robots.txt that you can track in your stats. Sometimes, however, it is nice to have an outsider’s perspective on robot behaviors in order to compare it to what you may have noticed. I view a lot of robots.txt files, and sites with and without them, so I’ve been able to come up with a few behavior patterns I would like to share with you.
MSNbotMSN’s search engine robot is called MSNbot. The MSNbot has quite a voracious appetite for spidering websites. Some webmasters love it and try to feed it as much as possible. Other webmasters don't see any reason to use up bandwidth for a search engine that doesn't bring them traffic. Either way, MSNbot will not spider your website unless you have the robots.txt. Once it finds your robots.txt, it will wander the site, almost timidly at first. Then MSNbot builds up courage and indexes files rapidly. So much so, that use of the crawl-delay directive is recommended with this robot. I’ll cover this more later.
Recent events could be the cause of this. Several months ago, MSN received many complaints that
MSNbot was ignoring directives written into the robots.txt files, such as crawling directories it has been instructed to stay out of. Engineers looked into the problem, and I believe they changed a few things to help control this type of behavior with the robot.
In the process, they may have changed it in such a way as to instruct the MSNbot to follow the robots.txt to the letter, and for websites that didn’t have one, it probably got confused and just left, not having a letter of the law to go by. While this is probably mere speculation, the spidering behavior of the robot seems to fit this assessment.
Yahoo’s Inktomi SlurpYahoo incorporated the use of Inktomi’s search engine crawler, and is now known as Slurp. Inktomi/Yahoo's Slurp seems to gobble greedily for a couple of days, disappear, come back, gobble more, and disappear again. Without the robots.txt, however, it will crawl fairly slowly, until it just kind of fades away, unless it finds great, unique content. But still, without the presence of the robots.txt, it may not crawl very deeply into your website.
GooglebotOn Google’s website, they instruct webmasters on the use of the robots.txt, and recommend that you do so. SEOs know that Google’s “guidelines” for webmasters are actually more like step by step directions on how to optimize for the search engine. So if Google makes mention of the robots.txt, then I would definitely follow those recommendations to a T.
Google will crawl a site,
robots.txt or no, sporadically either way, but it will heed the instructions in the file if it is there. Googlebot has been known to only crawl one or two levels deep without the presence of the robots.txt file.
IA_ArchiverAlexa’s search engine robot is called ia_archiver. It is an aggressive spider with a big appetite; however it is also very polite. It tends to limit its crawls to a couple hundred pages at a time, crawling without using extraneously large amounts of bandwidth, and slow enough as to not overload the server. It will continue its crawl over a couple of days, and then come back after that fairly consistently as well. So much so, that by analyzing your web stats, you can almost predict when ia_archiver will perform its next crawl. Alexa’s ia_archiver obeys the robots.txt commands and directives.
There are many other spiders and robots that exhibit particular behaviors when crawling your site. The good ones will follow the robots.txt directives, and many of the bad ones will not. Later, I’ll show you a few ways to help prevent some problems you might encounter from search engine robots, and how to utilize your robots.txt to help.Advanced Robots.txt Commands and Features
While the basic commands that make up a robots.txt file are two types of information, there are some commands and features that can be used. I should let you know, however, that not all search engine spiders understand these commands. It’s important to know which ones do and which do not.
Crawl Delay
Some robots have been known to crawl web pages at lightening speeds, forcing web servers to ban ip addresses from the robots, or disallowing them to crawl the websites. Some web servers have automatic flood triggers implemented, with automatic ip-banning software in place. If a search engine spider crawls too quickly, it can trigger these ip-bans, blocking the subsequent crawling activities of the search engine. While some of these robots would do well with a ban, there are others more likely that you do not wish banned.
Instead of the following example, which subsequently bans the robot from crawling any of your pages, another solution was offered to this problem. The crawl delay command.
User-agent: MSNbot
Disallow: /MSNbot was probably the most notorious offender. In an SEO forum,
“msndude” gave some insight into this: “With regards to aggressiveness of the crawl: we are definitely learning and improving. We take politeness very seriously and we work hard to make sure that we are fixing issues as they come up…
I also want to make folks aware of a feature that MSNbot supports…what we call a crawl delay
.
Basically it allows you to specify via robots.txt an amount of time (in seconds) that MSNbot should wait before retrieving another page from that host. The syntax in your robots.txt file would look something like:
User-Agent: MSNbot
Crawl-Delay: 20“This instructs MSNbot to wait 20 seconds before retrieving another page from that host. If you think that MSNbot is being a bit aggressive this is a way to have it slow down on your host while still making sure that your pages are indexed.”
Other search engine spiders that support this command are Slurp, Ocelli, Teoma/AskJeeves, Spiderline and many others.
Googlebot does not officially support this command, however it is usually fairly well-mannered and doesn’t need it. If you are not sure which robots understand this command, a simple question presented to the search engine’s support team could easily help you with this. There is a good list of search engine robots at
RobotsTxt.org with contact information if you are unsure how to reach them. It’s not always easy to know which website the robot belongs to. You may not know, for example, that
Slurp belongs to Yahoo, or that
Scooter belonged to AltaVista.
Meta Tag InstructionsWith the availability of search engine robot technology, there are thousands of search engine robots. There just isn’t a way to list them all, along with their capabilities and disadvantages. Many of these lesser known robots don’t even attempt to view your robots.txt. So what do you do then? Many webmasters find it handy to be able to place a few commands directly into their meta tags to instruct robots. These tags are placed in the "head" section like any other meta tags.
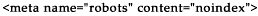
This meta tag above tells the robot not to index this page.
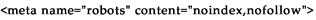
This tag above tells a robot should neither index this document, nor analyze it for links.
Other tags you might have use of are below:

Unfortunately, there is no way to guarantee that these less than polite robots will follow your instructions in your meta tags any more than they will follow your robots.txt. In these extreme cases, it would be to your benefit to view your server logs, find out the ip address of this erring robot, and just ban it.
Bandwidth LimitationsAnother complaint for having a search engine spider crawl un-instructed lies in the area of bandwidth. A search engine spider could easily eat up a gigabyte of bandwidth in a single crawl. For those of you paying for only so much bandwidth, this could be a big, if not just expensive, problem.
Without a robots.txt file, search engine spiders will request it anyway, causing a
404 Error to be presented. If you have a custom 404 Page Not Found error page, then you are going to be wasting bandwidth. A robots.txt file is a small file, and will cause less bandwidth usage than not having one. Usually the crawl-delay directive can help with this.
Some webmasters believe that another good way to keep a search engine spider from using too much bandwidth is with the revisit-after tag. However, many believe this to be a myth.
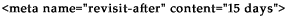
Most search engine robots, like Google, do not honor this command. If you feel that Googlebot is crawling too frequently and using too much bandwidth, you can visit Google’s help pages and fill out a form requesting Googlebot to crawl your site less often.
You can also block all robots except the ones you specify, as well as provide different sets of instructions for different robots. The robots.txt file is very flexible in this way.
Using Robots.txt for Corporate SecurityWhile some of you are familiar with a company called Perfect 10 and its security issues, some are not. Perfect 10 is an adult company with copyrighted pictures of models. They filed a preliminary injunction against Google in August of 2005. According to BusinessWire.com, “The motion for preliminary injunction seeks to enjoin Google from copying, displaying, and distributing Perfect 10 copyrighted images. Perfect 10 filed a complaint against Google, Inc. for copyright infringement and other claims in November of 2004. It is Perfect 10's contention that Google is displaying hundreds of thousands of adult images, from the most tame to the most exceedingly explicit, to draw massive traffic to its web site, which it is converting into hundreds of millions of dollars of advertising revenue. Perfect 10 claims that under the guise of being a "search engine," Google is displaying, free of charge, thousands of copies of the best images from Perfect 10, Playboy, nude scenes from major movies, nude images of supermodels, as well as extremely explicit images of all kinds. Perfect 10 contends that it has sent 35 notices of infringement to Google covering over 6,500 infringing URLs, but that Google continues to display over 3,000 Perfect 10 copyrighted images without authorization.”
What is interesting in this situation is that the blame actually lies with Perfect 10, Inc. The company failed to direct the search engine to stay out of its image directory. Two simple lines in a robots.txt file on their web server would have easily barred Google from indexing these images in the first place, a practice which Google themselves mention in their guidelines for webmasters.
User-agent: Googlebot-Image
Disallow: /imagesOne good piece of advice given in an SEO forum is this: “If you want to keep something private on the web, .htaccess and passwords are your friends. If you want to keep something out of Google (or any other search engine), robots.txt and meta tags are your friends. If someone can type a URL into a browser and find your page, don't count on a secret URL remaining secret. Use passwords or robots.txt to protect data.”
Using robots.txt to keep search engines out of sensitive areas is a simple task, and a step that every webmaster has use of. Search engines have been known to index members-only areas, development documents, and even employee personnel records. It is the responsibility of the webmaster to ensure the protection of their sensitive data and copyrighted material. A search engine spider cannot be expected to know the difference between copyrighted material and other data, especially when it makes it clear what would be an easy deterrent to this type of behavior. This is one of the many consequences a webmaster will face if they do not utilize their robots.txt file.
Between Clint’s article and this one, I hope you understand the importance of using a robots.txt on your web server. Ultimately, it’s up to you to help control the behaviors of search engine robots when spidering your site’s pages. Using robots.txt is easy, and there is no excuse for lack of security, spider bandwidth issues or not getting indexed because you failed to do this simple thing. If you need help generating a robots.txt, there are many websites that give you step by step instructions, or can even generate the file for you. With this powerful tool at your disposal, you need to make use of it. It’s your own fault if you don’t.